인사말
건강한 삶과 행복,환한 웃음으로 좋은벗이 되겠습니다

DeepSeek V3: Advanced AI Language Model
페이지 정보
작성자 Susie 작성일25-02-03 09:05 조회6회 댓글0건본문
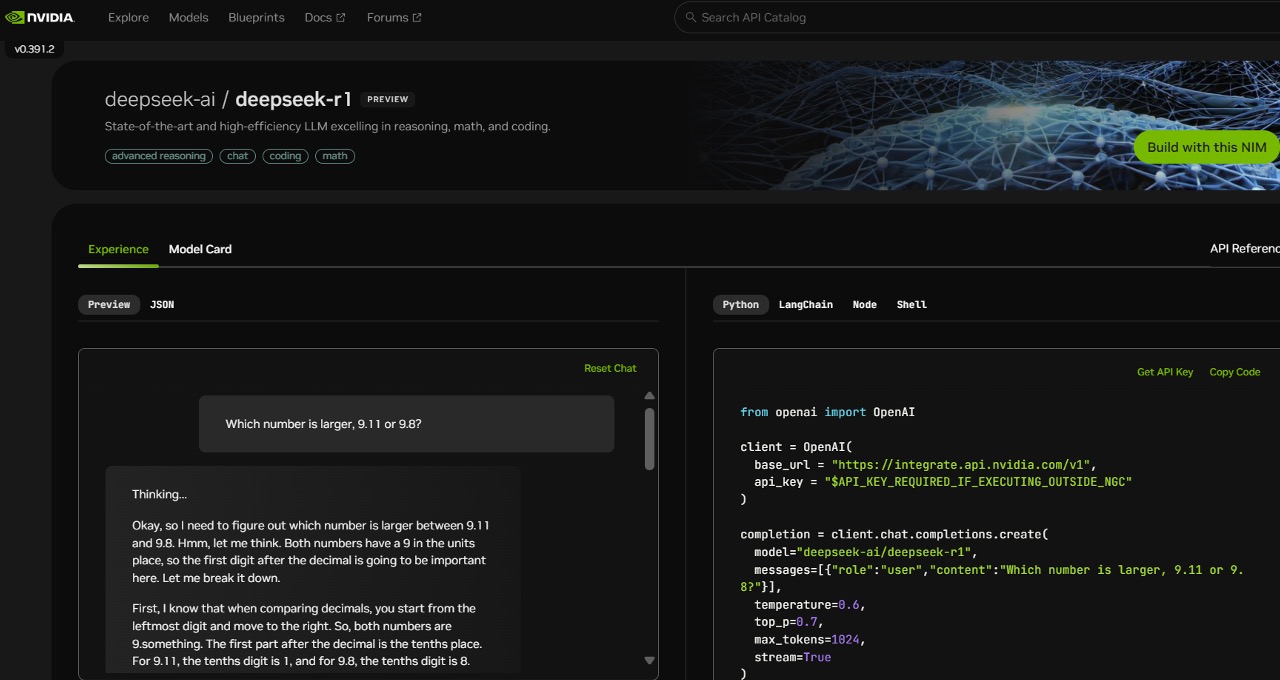 Hackers are using malicious knowledge packages disguised as the Chinese chatbot DeepSeek for attacks on web builders and tech enthusiasts, the knowledge safety company Positive Technologies informed TASS. Quantization degree, the datatype of the mannequin weights and the way compressed the mannequin weights are. Although our tile-sensible high-quality-grained quantization successfully mitigates the error launched by function outliers, it requires different groupings for activation quantization, i.e., 1x128 in forward move and 128x1 for backward pass. You possibly can run fashions that can method Claude, but when you may have at greatest 64GBs of memory for more than 5000 USD, there are two issues fighting in opposition to your particular scenario: these GBs are better fitted to tooling (of which small fashions may be a part of), and your money higher spent on dedicated hardware for LLMs. Regardless of the case could also be, builders have taken to DeepSeek’s models, which aren’t open source because the phrase is often understood however are available under permissive licenses that permit for commercial use. DeepSeek v3 represents the newest advancement in giant language models, featuring a groundbreaking Mixture-of-Experts architecture with 671B whole parameters. 8 GB of RAM out there to run the 7B fashions, 16 GB to run the 13B fashions, and 32 GB to run the 33B fashions.
Hackers are using malicious knowledge packages disguised as the Chinese chatbot DeepSeek for attacks on web builders and tech enthusiasts, the knowledge safety company Positive Technologies informed TASS. Quantization degree, the datatype of the mannequin weights and the way compressed the mannequin weights are. Although our tile-sensible high-quality-grained quantization successfully mitigates the error launched by function outliers, it requires different groupings for activation quantization, i.e., 1x128 in forward move and 128x1 for backward pass. You possibly can run fashions that can method Claude, but when you may have at greatest 64GBs of memory for more than 5000 USD, there are two issues fighting in opposition to your particular scenario: these GBs are better fitted to tooling (of which small fashions may be a part of), and your money higher spent on dedicated hardware for LLMs. Regardless of the case could also be, builders have taken to DeepSeek’s models, which aren’t open source because the phrase is often understood however are available under permissive licenses that permit for commercial use. DeepSeek v3 represents the newest advancement in giant language models, featuring a groundbreaking Mixture-of-Experts architecture with 671B whole parameters. 8 GB of RAM out there to run the 7B fashions, 16 GB to run the 13B fashions, and 32 GB to run the 33B fashions.
 Ollama lets us run large language models regionally, it comes with a fairly easy with a docker-like cli interface to begin, stop, pull and list processes. LLama(Large Language Model Meta AI)3, the next generation of Llama 2, Trained on 15T tokens (7x more than Llama 2) by Meta is available in two sizes, the 8b and 70b version. DHS has special authorities to transmit info referring to particular person or group AIS account exercise to, reportedly, the FBI, the CIA, the NSA, the State Department, the Department of Justice, the Department of Health and Human Services, and more. There’s plenty of YouTube videos on the topic with more details and demos of performance. Chatbot performance is a posh matter," he mentioned. "If the claims hold up, this could be one other instance of Chinese builders managing to roughly replicate U.S. This model affords comparable efficiency to superior fashions like ChatGPT o1 however was reportedly developed at a much decrease price. The API will possible assist you complete or generate chat messages, similar to how conversational AI models work.
Ollama lets us run large language models regionally, it comes with a fairly easy with a docker-like cli interface to begin, stop, pull and list processes. LLama(Large Language Model Meta AI)3, the next generation of Llama 2, Trained on 15T tokens (7x more than Llama 2) by Meta is available in two sizes, the 8b and 70b version. DHS has special authorities to transmit info referring to particular person or group AIS account exercise to, reportedly, the FBI, the CIA, the NSA, the State Department, the Department of Justice, the Department of Health and Human Services, and more. There’s plenty of YouTube videos on the topic with more details and demos of performance. Chatbot performance is a posh matter," he mentioned. "If the claims hold up, this could be one other instance of Chinese builders managing to roughly replicate U.S. This model affords comparable efficiency to superior fashions like ChatGPT o1 however was reportedly developed at a much decrease price. The API will possible assist you complete or generate chat messages, similar to how conversational AI models work.
Apidog is an all-in-one platform designed to streamline API design, growth, and testing workflows. Along with your API keys in hand, you are actually able to explore the capabilities of the Deepseek API. Within every role, authors are listed alphabetically by the primary name. This is the primary such superior AI system out there to customers without cost. It was subsequently found that Dr. Farnhaus had been conducting anthropological analysis of pedophile traditions in a variety of overseas cultures and queries made to an undisclosed AI system had triggered flags on his AIS-linked profile. You might want to know what options you might have and how the system works on all levels. How a lot RAM do we need? The RAM utilization is dependent on the model you employ and if its use 32-bit floating-point (FP32) representations for model parameters and activations or 16-bit floating-point (FP16). I've a m2 professional with 32gb of shared ram and a desktop with a 8gb RTX 2070, Gemma 2 9b q8 runs very properly for following directions and doing textual content classification.
However, after some struggles with Synching up a few Nvidia GPU’s to it, we tried a special strategy: running Ollama, which on Linux works very effectively out of the field. Don’t miss out on the opportunity to harness the mixed power of Deep Seek and Apidog. I don’t know if mannequin coaching is better as pytorch doesn’t have a local version for apple silicon. Low-precision training has emerged as a promising resolution for efficient training (Kalamkar et al., 2019; Narang et al., 2017; Peng et al., 2023b; Dettmers et al., 2022), its evolution being carefully tied to developments in hardware capabilities (Micikevicius et al., 2022; Luo et al., 2024; Rouhani et al., 2023a). On this work, we introduce an FP8 mixed precision coaching framework and, for the primary time, validate its effectiveness on an especially massive-scale model. Inspired by recent advances in low-precision training (Peng et al., 2023b; Dettmers et al., 2022; Noune et al., 2022), we suggest a nice-grained blended precision framework using the FP8 data format for coaching DeepSeek-V3. free deepseek-V3 is a powerful new AI mannequin launched on December 26, 2024, representing a significant development in open-supply AI know-how.
If you want to find out more information regarding ديب سيك مجانا review our web-page.
댓글목록
등록된 댓글이 없습니다.