인사말
건강한 삶과 행복,환한 웃음으로 좋은벗이 되겠습니다

What Everyone is Saying About Deepseek China Ai Is Dead Wrong And Why
페이지 정보
작성자 Alice 작성일25-02-16 05:42 조회9회 댓글0건본문
We accomplished a spread of analysis duties to research how components like programming language, the variety of tokens in the input, models used calculate the rating and the fashions used to supply our AI-written code, would affect the Binoculars scores and ultimately, how properly Binoculars was in a position to differentiate between human and AI-written code. A dataset containing human-written code information written in quite a lot of programming languages was collected, and equal AI-generated code files were produced utilizing GPT-3.5-turbo (which had been our default mannequin), GPT-4o, ChatMistralAI, and deepseek-coder-6.7b-instruct. First, we swapped our information supply to make use of the github-code-clear dataset, containing 115 million code files taken from GitHub. To analyze this, we tested three completely different sized fashions, particularly DeepSeek Coder 1.3B, IBM Granite 3B and CodeLlama 7B utilizing datasets containing Python and JavaScript code. To realize this, we developed a code-technology pipeline, which collected human-written code and used it to produce AI-written recordsdata or individual functions, relying on the way it was configured. This, coupled with the fact that performance was worse than random chance for enter lengths of 25 tokens, prompt that for Binoculars to reliably classify code as human or AI-written, there may be a minimal enter token size requirement.
The above ROC Curve shows the identical findings, with a transparent cut up in classification accuracy once we compare token lengths above and under 300 tokens. However, from 200 tokens onward, the scores for AI-written code are generally decrease than human-written code, with growing differentiation as token lengths develop, that means that at these longer token lengths, Binoculars would higher be at classifying code as either human or AI-written. The above graph shows the average Binoculars score at each token size, for human and AI-written code. This resulted in a giant enchancment in AUC scores, particularly when considering inputs over 180 tokens in size, confirming our findings from our effective token size investigation. Amongst the models, GPT-4o had the bottom Binoculars scores, indicating its AI-generated code is more simply identifiable despite being a state-of-the-art mannequin. The original Binoculars paper recognized that the variety of tokens within the input impacted detection performance, so we investigated if the same utilized to code. Then, we take the original code file, and substitute one perform with the AI-written equal. We then take this modified file, and the unique, human-written version, and discover the "diff" between them. Our outcomes confirmed that for Python code, all the fashions usually produced greater Binoculars scores for human-written code compared to AI-written code.
These findings were particularly surprising, as a result of we anticipated that the state-of-the-artwork models, like GPT-4o would be in a position to produce code that was probably the most like the human-written code information, and hence would achieve related Binoculars scores and be tougher to establish. It could possibly be the case that we were seeing such good classification results because the standard of our AI-written code was poor. To get a sign of classification, we also plotted our outcomes on a ROC Curve, which reveals the classification performance across all thresholds. The ROC curve further confirmed a greater distinction between GPT-4o-generated code and human code in comparison with other models. The ROC curves indicate that for Python, the selection of model has little impression on classification performance, whereas for JavaScript, smaller models like Free DeepSeek online 1.3B perform higher in differentiating code sorts. We see the identical pattern for JavaScript, with Free DeepSeek online displaying the biggest difference. Next, we looked at code on the function/technique stage to see if there's an observable distinction when things like boilerplate code, imports, licence statements aren't present in our inputs. For inputs shorter than a hundred and fifty tokens, there's little distinction between the scores between human and AI-written code. With our datasets assembled, we used Binoculars to calculate the scores for each the human and AI-written code.
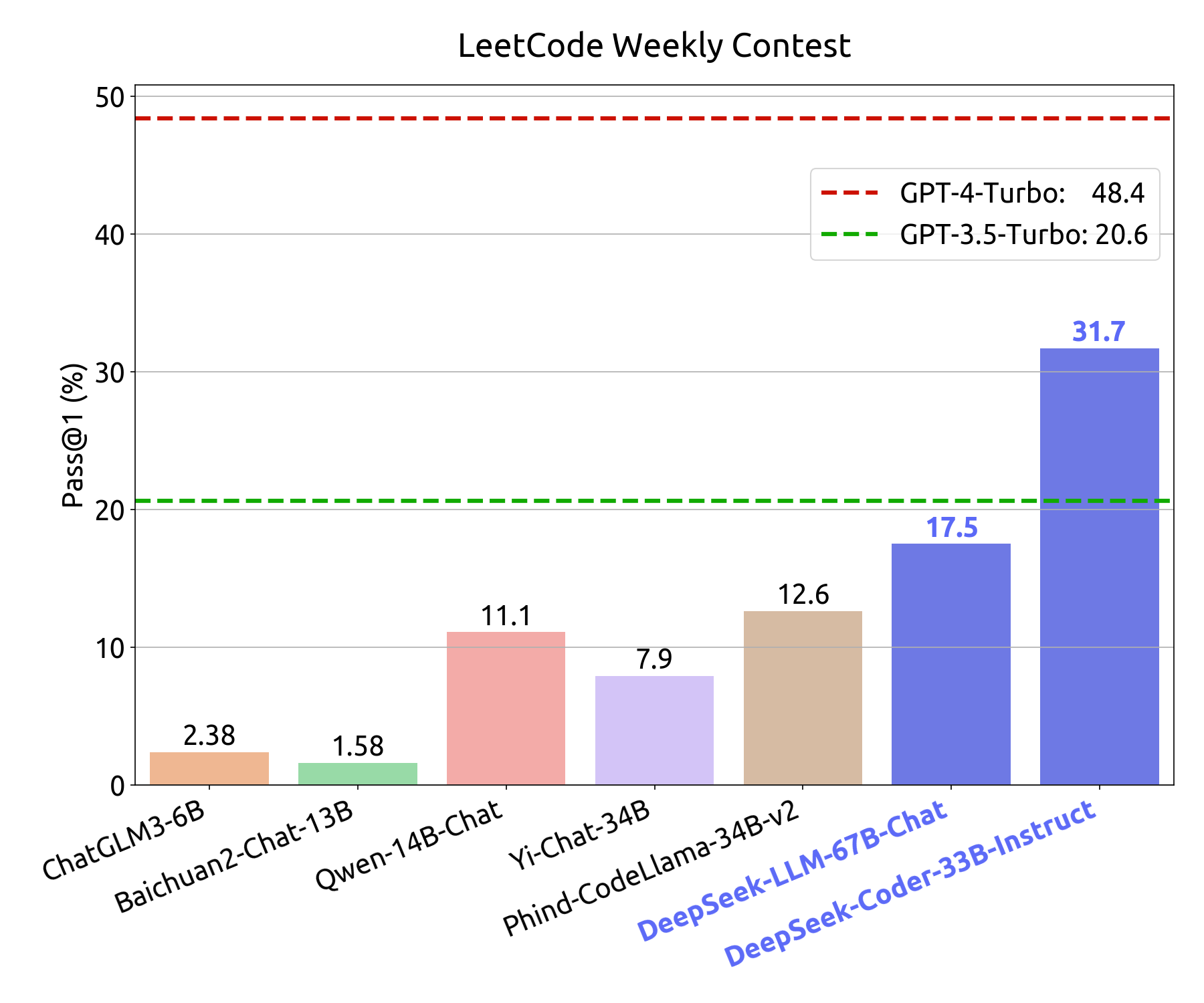 Additionally, within the case of longer information, the LLMs had been unable to seize all of the performance, so the resulting AI-written information had been usually filled with feedback describing the omitted code. To make sure that the code was human written, we selected repositories that had been archived earlier than the discharge of Generative AI coding tools like GitHub Copilot. First, we provided the pipeline with the URLs of some GitHub repositories and used the GitHub API to scrape the recordsdata within the repositories. Firstly, the code we had scraped from GitHub contained numerous quick, config files which were polluting our dataset. However, the scale of the fashions were small in comparison with the size of the github-code-clean dataset, and we were randomly sampling this dataset to supply the datasets used in our investigations. With the source of the difficulty being in our dataset, the obvious solution was to revisit our code era pipeline. The total coaching dataset, as nicely as the code used in training, remains hidden.
Additionally, within the case of longer information, the LLMs had been unable to seize all of the performance, so the resulting AI-written information had been usually filled with feedback describing the omitted code. To make sure that the code was human written, we selected repositories that had been archived earlier than the discharge of Generative AI coding tools like GitHub Copilot. First, we provided the pipeline with the URLs of some GitHub repositories and used the GitHub API to scrape the recordsdata within the repositories. Firstly, the code we had scraped from GitHub contained numerous quick, config files which were polluting our dataset. However, the scale of the fashions were small in comparison with the size of the github-code-clean dataset, and we were randomly sampling this dataset to supply the datasets used in our investigations. With the source of the difficulty being in our dataset, the obvious solution was to revisit our code era pipeline. The total coaching dataset, as nicely as the code used in training, remains hidden.
댓글목록
등록된 댓글이 없습니다.