인사말
건강한 삶과 행복,환한 웃음으로 좋은벗이 되겠습니다

Deepseek Ai News Made Easy - Even Your Kids Can Do It
페이지 정보
작성자 Gregory 작성일25-02-27 13:29 조회7회 댓글0건본문
Developers on Hugging Face have also snapped up new open-source models from the Chinese tech giants Tencent and Alibaba. From a builders point-of-view the latter option (not catching the exception and failing) is preferable, since a NullPointerException is often not wished and the test subsequently factors to a bug. Beyond self-rewarding, we're additionally devoted to uncovering other general and scalable rewarding methods to constantly advance the model capabilities on the whole situations. However, in more general scenarios, constructing a feedback mechanism by way of hard coding is impractical. However, many are suspicious concerning the timing of the launch of DeepSeek’s R1 model, particularly at a time when Donald Trump had just grow to be president of the US. This comes at a time when different American tech companies like Microsoft and Meta are committing vast sums to build GPU-packed knowledge centres, reinforcing the narrative that computational power is the key to AI supremacy. The social media big for a while has tried to stability the ramp up of newer, lower-monetizing surfaces that are in style with users, resembling short-form video Reels, with improved precision for mature advertising formats.
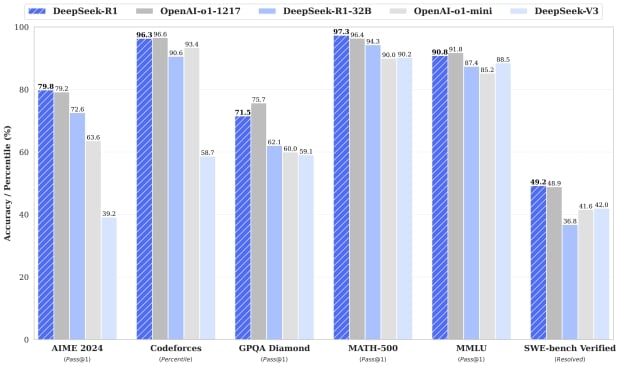 To maintain a steadiness between model accuracy and computational effectivity, we rigorously chosen optimal settings for Free DeepSeek online-V3 in distillation. • We are going to consistently study and refine our mannequin architectures, aiming to further improve both the training and inference efficiency, striving to method efficient support for infinite context size. While our current work focuses on distilling data from arithmetic and coding domains, this approach exhibits potential for broader applications throughout numerous process domains. • We will repeatedly iterate on the amount and quality of our training information, and explore the incorporation of additional coaching signal sources, aiming to drive data scaling across a more complete range of dimensions. ChatGPT’s answer was extra nuanced. This assortment is just like that of different generative AI platforms that take in consumer prompts to answer questions. This means to rapidly iterate permits China to take current technologies and push them towards their optimum form, making them more efficient, value-efficient, and extensively accessible. Fortunately, these limitations are expected to be naturally addressed with the development of more superior hardware. The far more lengthy-reaching impact it could have would not be technological, it could be political, for it could disrupt the paradigms entrenched within the tech business in substantive ways.
To maintain a steadiness between model accuracy and computational effectivity, we rigorously chosen optimal settings for Free DeepSeek online-V3 in distillation. • We are going to consistently study and refine our mannequin architectures, aiming to further improve both the training and inference efficiency, striving to method efficient support for infinite context size. While our current work focuses on distilling data from arithmetic and coding domains, this approach exhibits potential for broader applications throughout numerous process domains. • We will repeatedly iterate on the amount and quality of our training information, and explore the incorporation of additional coaching signal sources, aiming to drive data scaling across a more complete range of dimensions. ChatGPT’s answer was extra nuanced. This assortment is just like that of different generative AI platforms that take in consumer prompts to answer questions. This means to rapidly iterate permits China to take current technologies and push them towards their optimum form, making them more efficient, value-efficient, and extensively accessible. Fortunately, these limitations are expected to be naturally addressed with the development of more superior hardware. The far more lengthy-reaching impact it could have would not be technological, it could be political, for it could disrupt the paradigms entrenched within the tech business in substantive ways.
The Bank of China’s newest AI initiative is merely considered one of the many projects that Beijing has pushed in the trade through the years. I've just pointed that Vite might not at all times be reliable, based alone expertise, and backed with a GitHub problem with over 400 likes. Second, Korea must prioritize originality over blind adherence to world developments. The submit-coaching also makes successful in distilling the reasoning capability from the DeepSeek-R1 series of fashions. We ablate the contribution of distillation from DeepSeek-R1 primarily based on DeepSeek-V2.5. Our experiments reveal an fascinating trade-off: the distillation leads to better performance but additionally considerably will increase the typical response size. While acknowledging its sturdy efficiency and price-effectiveness, we also acknowledge that DeepSeek-V3 has some limitations, particularly on the deployment. During the development of Free DeepSeek-V3, for these broader contexts, we employ the constitutional AI strategy (Bai et al., 2022), leveraging the voting evaluation outcomes of DeepSeek-V3 itself as a suggestions supply. Further exploration of this approach throughout totally different domains remains an essential course for future analysis.
By integrating extra constitutional inputs, DeepSeek-V3 can optimize in the direction of the constitutional path. Our analysis means that data distillation from reasoning models presents a promising direction for put up-coaching optimization. Table 8 presents the efficiency of those models in RewardBench (Lambert et al., 2024). DeepSeek-V3 achieves efficiency on par with the perfect variations of GPT-4o-0806 and Claude-3.5-Sonnet-1022, while surpassing other versions. Similarly, DeepSeek-V3 showcases distinctive performance on AlpacaEval 2.0, outperforming each closed-source and open-source fashions. Furthermore, DeepSeek-V3 achieves a groundbreaking milestone as the first open-supply mannequin to surpass 85% on the Arena-Hard benchmark. In this convoluted world of artificial intelligence, while main gamers like OpenAI and Google have dominated headlines with their groundbreaking developments, new challengers are emerging with fresh ideas and bold strategies. Individuals who are not conscious, when they begin utilizing DeepSeek, the platform is by deault set to DeepSeek r1-V3 version. We compare the judgment potential of DeepSeek-V3 with state-of-the-artwork fashions, specifically GPT-4o and Claude-3.5.
댓글목록
등록된 댓글이 없습니다.