인사말
건강한 삶과 행복,환한 웃음으로 좋은벗이 되겠습니다

The Next Three Things To Immediately Do About Deepseek
페이지 정보
작성자 Ermelinda 작성일25-02-27 16:04 조회7회 댓글0건본문
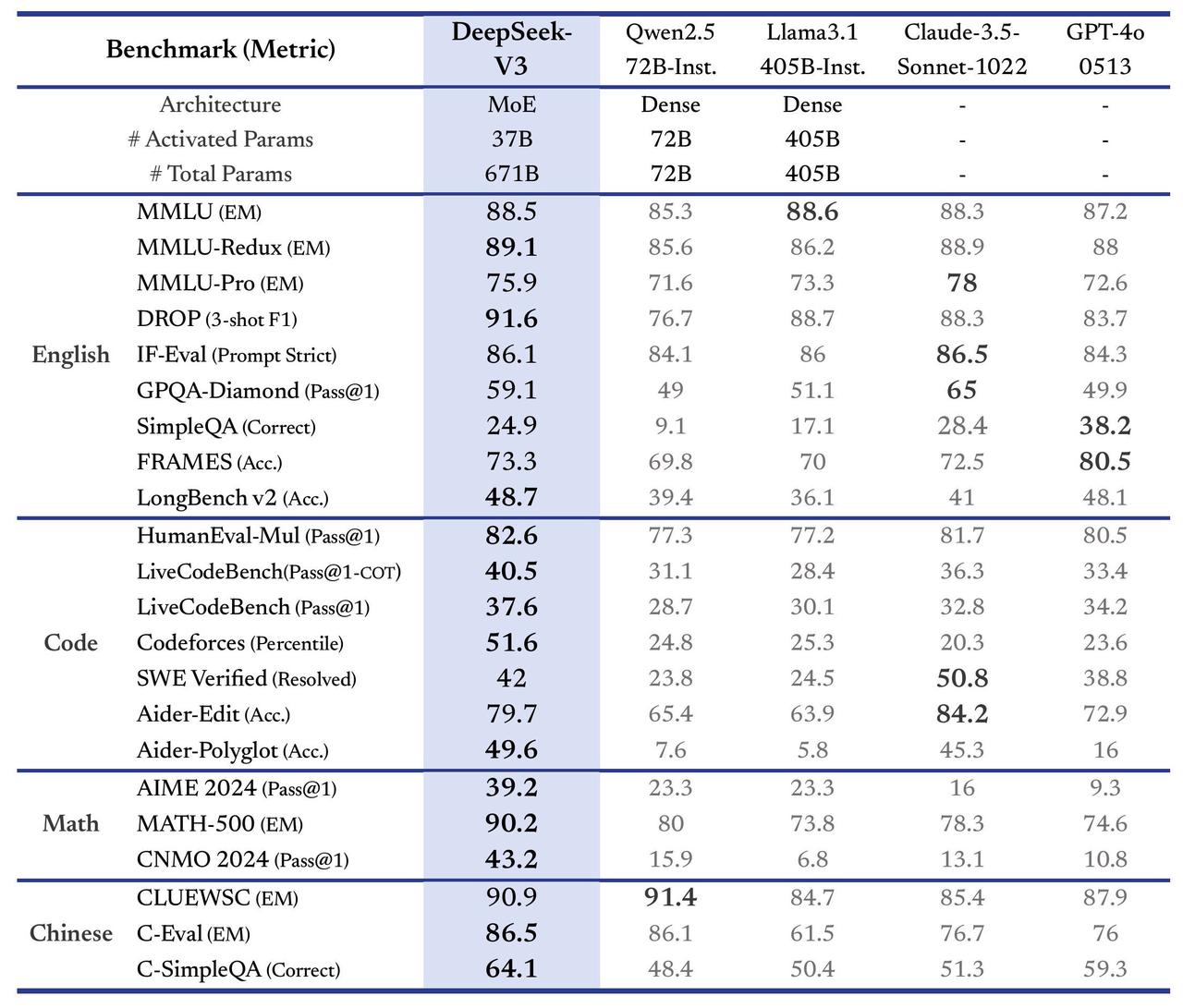 DeepSeek has achieved both at much decrease prices than the latest US-made fashions. Many people are concerned concerning the power calls for and related environmental impact of AI training and inference, and it is heartening to see a improvement that could lead to more ubiquitous AI capabilities with a much decrease footprint. Already, others are replicating the high-efficiency, low-cost training method of DeepSeek. Much has already been made of the apparent plateauing of the "extra knowledge equals smarter models" method to AI development. This bias is usually a mirrored image of human biases found in the info used to practice AI fashions, and researchers have put a lot effort into "AI alignment," the technique of attempting to eradicate bias and align AI responses with human intent. All AI fashions have the potential for bias of their generated responses. However, it's not laborious to see the intent behind DeepSeek's fastidiously-curated refusals, and as exciting as the open-source nature of DeepSeek is, one must be cognizant that this bias will likely be propagated into any future models derived from it. Its an revolutionary AI platform developed by a Chinese startup that focuses on slicing-edge artificial intelligence fashions.
DeepSeek has achieved both at much decrease prices than the latest US-made fashions. Many people are concerned concerning the power calls for and related environmental impact of AI training and inference, and it is heartening to see a improvement that could lead to more ubiquitous AI capabilities with a much decrease footprint. Already, others are replicating the high-efficiency, low-cost training method of DeepSeek. Much has already been made of the apparent plateauing of the "extra knowledge equals smarter models" method to AI development. This bias is usually a mirrored image of human biases found in the info used to practice AI fashions, and researchers have put a lot effort into "AI alignment," the technique of attempting to eradicate bias and align AI responses with human intent. All AI fashions have the potential for bias of their generated responses. However, it's not laborious to see the intent behind DeepSeek's fastidiously-curated refusals, and as exciting as the open-source nature of DeepSeek is, one must be cognizant that this bias will likely be propagated into any future models derived from it. Its an revolutionary AI platform developed by a Chinese startup that focuses on slicing-edge artificial intelligence fashions.
On the face of it, it's simply a brand new Chinese AI model, and there’s no shortage of these launching each week. When the scarcity of high-efficiency GPU chips among domestic cloud suppliers grew to become probably the most direct factor limiting the delivery of China's generative AI, in line with "Caijing Eleven People (a Chinese media outlet)," there are not more than five companies in China with over 10,000 GPUs. This leads us to Chinese AI startup DeepSeek. DeepSeek is shaking up the AI business with cost-efficient massive-language models it claims can perform just as well as rivals from giants like OpenAI and Meta. In the long run, what we're seeing here is the commoditization of foundational AI fashions. Here once more it seems plausible that DeepSeek benefited from distillation, significantly in terms of coaching R1. We're right here to help you understand how you can provide this engine a try within the safest potential car. If e.g. every subsequent token offers us a 15% relative discount in acceptance, it is likely to be possible to squeeze out some extra gain from this speculative decoding setup by predicting a couple of extra tokens out. Free DeepSeek r1 v3 only uses multi-token prediction as much as the second next token, and the acceptance fee the technical report quotes for second token prediction is between 85% and 90%. This is sort of impressive and should allow nearly double the inference velocity (in items of tokens per second per consumer) at a fixed value per token if we use the aforementioned speculative decoding setup.
Transformer structure: At its core, DeepSeek-V2 makes use of the Transformer architecture, which processes textual content by splitting it into smaller tokens (like words or subwords) and then uses layers of computations to understand the relationships between these tokens. The fashions can then be run by yourself hardware using instruments like ollama. Through the years, I've used many developer instruments, developer productivity tools, and general productiveness instruments like Notion and many others. Most of these instruments, have helped get better at what I wanted to do, brought sanity in several of my workflows. DeepSeek is mainly a sophisticated AI model developed by Liang Wenfeng, a Chinese developer. Within the case of DeepSeek, certain biased responses are deliberately baked right into the mannequin: as an example, it refuses to interact in any discussion of Tiananmen Square or different, fashionable controversies related to the Chinese authorities. Those involved with the geopolitical implications of a Chinese company advancing in AI ought to feel encouraged: researchers and corporations everywhere in the world are rapidly absorbing and incorporating the breakthroughs made by DeepSeek. This also explains why Softbank (and whatever investors Masayoshi Son brings collectively) would offer the funding for OpenAI that Microsoft is not going to: the assumption that we are reaching a takeoff level the place there'll the truth is be actual returns in direction of being first.
![]() The third is the diversity of the models being used after we gave our builders freedom to pick what they wish to do. If you want to learn about DeepSeek prompts for other industries, you can check out this information on 100 use instances and DeepSeek example prompts. Vary sentence structure, use numerous vocabulary, and inject your own persona. Do not use this model in services made available to end customers. You may choose how you can deploy DeepSeek-R1 models on AWS in the present day in a couple of ways: 1/ Amazon Bedrock Marketplace for the DeepSeek-R1 mannequin, 2/ Amazon SageMaker JumpStart for the DeepSeek-R1 mannequin, free Deep seek 3/ Amazon Bedrock Custom Model Import for the DeepSeek-R1-Distill models, and 4/ Amazon EC2 Trn1 situations for the DeepSeek-R1-Distill fashions. Additionally, you may as well use AWS Trainium and AWS Inferentia to deploy DeepSeek Ai Chat-R1-Distill fashions price-effectively by way of Amazon Elastic Compute Cloud (Amazon EC2) or Amazon SageMaker AI. Confer with the Provided Files table below to see what recordsdata use which methods, and the way. For more, see this glorious YouTube explainer. For a superb discussion on DeepSeek and its security implications, see the most recent episode of the practical AI podcast.
The third is the diversity of the models being used after we gave our builders freedom to pick what they wish to do. If you want to learn about DeepSeek prompts for other industries, you can check out this information on 100 use instances and DeepSeek example prompts. Vary sentence structure, use numerous vocabulary, and inject your own persona. Do not use this model in services made available to end customers. You may choose how you can deploy DeepSeek-R1 models on AWS in the present day in a couple of ways: 1/ Amazon Bedrock Marketplace for the DeepSeek-R1 mannequin, 2/ Amazon SageMaker JumpStart for the DeepSeek-R1 mannequin, free Deep seek 3/ Amazon Bedrock Custom Model Import for the DeepSeek-R1-Distill models, and 4/ Amazon EC2 Trn1 situations for the DeepSeek-R1-Distill fashions. Additionally, you may as well use AWS Trainium and AWS Inferentia to deploy DeepSeek Ai Chat-R1-Distill fashions price-effectively by way of Amazon Elastic Compute Cloud (Amazon EC2) or Amazon SageMaker AI. Confer with the Provided Files table below to see what recordsdata use which methods, and the way. For more, see this glorious YouTube explainer. For a superb discussion on DeepSeek and its security implications, see the most recent episode of the practical AI podcast.
댓글목록
등록된 댓글이 없습니다.