인사말
건강한 삶과 행복,환한 웃음으로 좋은벗이 되겠습니다

Three Most Amazing Deepseek Changing How We See The World
페이지 정보
작성자 Gregorio 작성일25-03-02 12:07 조회8회 댓글0건본문
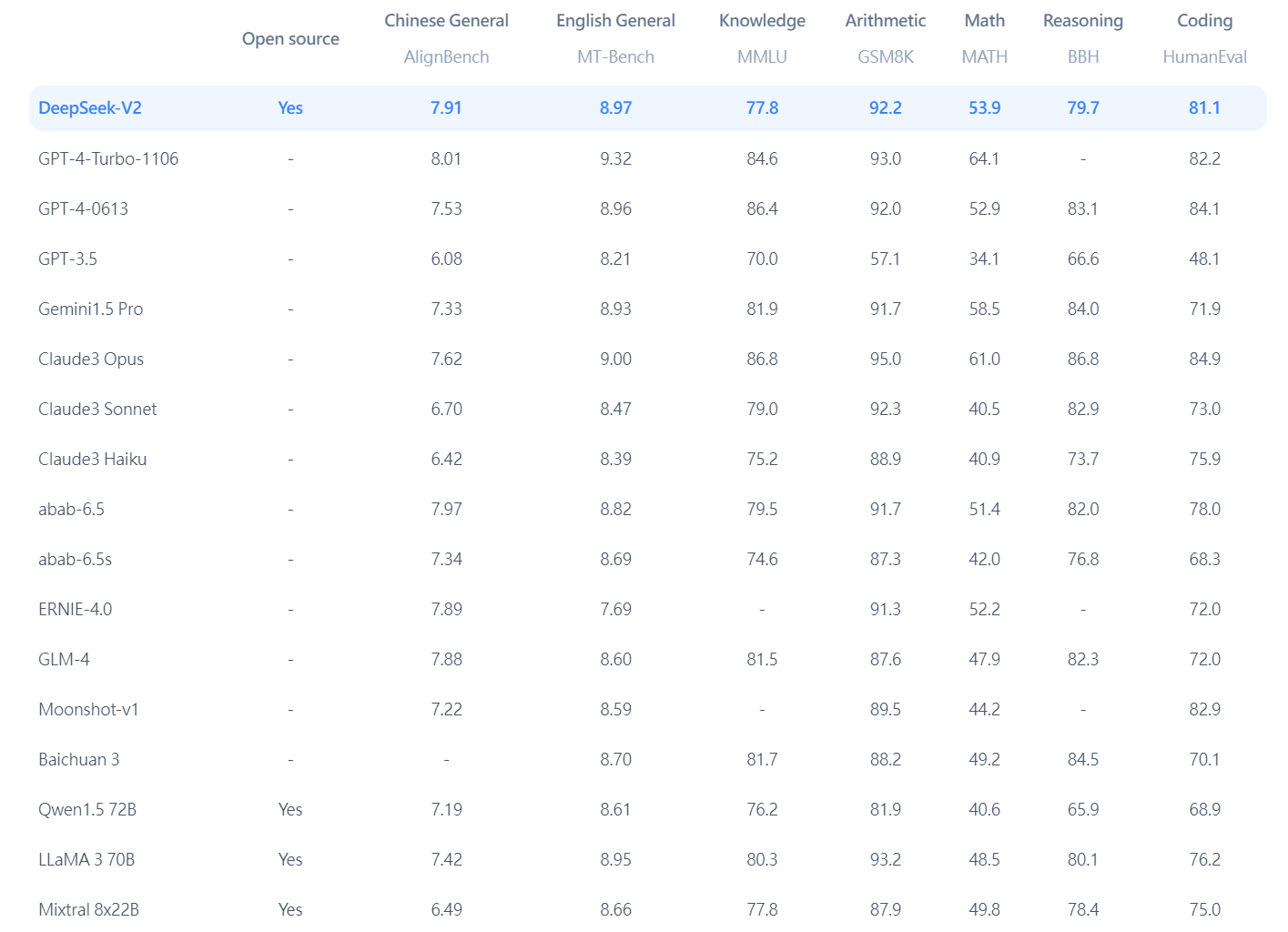 DeepSeek V3 is accessible via an internet demo platform and API service, providing seamless entry for varied purposes. Free DeepSeek Chat also gives a cell-pleasant expertise, allowing customers to access their accounts on the go. Apple Silicon uses unified memory, which signifies that the CPU, GPU, and NPU (neural processing unit) have entry to a shared pool of memory; this means that Apple’s high-finish hardware actually has the best shopper chip for inference (Nvidia gaming GPUs max out at 32GB of VRAM, whereas Apple’s chips go as much as 192 GB of RAM). I already laid out final fall how every side of Meta’s business advantages from AI; a big barrier to realizing that imaginative and prescient is the price of inference, which implies that dramatically cheaper inference - and dramatically cheaper training, given the need for Meta to stay on the innovative - makes that imaginative and prescient rather more achievable. That mentioned, we'll still need to await the complete details of R1 to come back out to see how a lot of an edge Deepseek free has over others. DeepSeek claimed the mannequin coaching took 2,788 thousand H800 GPU hours, which, at a cost of $2/GPU hour, comes out to a mere $5.576 million.
DeepSeek V3 is accessible via an internet demo platform and API service, providing seamless entry for varied purposes. Free DeepSeek Chat also gives a cell-pleasant expertise, allowing customers to access their accounts on the go. Apple Silicon uses unified memory, which signifies that the CPU, GPU, and NPU (neural processing unit) have entry to a shared pool of memory; this means that Apple’s high-finish hardware actually has the best shopper chip for inference (Nvidia gaming GPUs max out at 32GB of VRAM, whereas Apple’s chips go as much as 192 GB of RAM). I already laid out final fall how every side of Meta’s business advantages from AI; a big barrier to realizing that imaginative and prescient is the price of inference, which implies that dramatically cheaper inference - and dramatically cheaper training, given the need for Meta to stay on the innovative - makes that imaginative and prescient rather more achievable. That mentioned, we'll still need to await the complete details of R1 to come back out to see how a lot of an edge Deepseek free has over others. DeepSeek claimed the mannequin coaching took 2,788 thousand H800 GPU hours, which, at a cost of $2/GPU hour, comes out to a mere $5.576 million.
 So no, you can’t replicate DeepSeek the corporate for $5.576 million. OpenAI does not have some kind of particular sauce that can’t be replicated. R1 is notable, nonetheless, because o1 stood alone as the one reasoning model on the market, and the clearest sign that OpenAI was the market chief. This breakthrough in lowering expenses while growing effectivity and maintaining the mannequin's performance energy and quality in the AI industry sent "shockwaves" through the market. Why price efficiency matter in AI? I asked why the stock prices are down; you simply painted a constructive picture! Is that this why all of the massive Tech stock costs are down? Actually, the rationale why I spent a lot time on V3 is that that was the mannequin that really demonstrated quite a lot of the dynamics that seem to be generating so much shock and controversy. It has the power to suppose through an issue, producing much increased high quality outcomes, particularly in areas like coding, math, and logic (but I repeat myself). Another large winner is Amazon: AWS has by-and-large did not make their very own high quality model, however that doesn’t matter if there are very high quality open source models that they can serve at far decrease costs than expected.
So no, you can’t replicate DeepSeek the corporate for $5.576 million. OpenAI does not have some kind of particular sauce that can’t be replicated. R1 is notable, nonetheless, because o1 stood alone as the one reasoning model on the market, and the clearest sign that OpenAI was the market chief. This breakthrough in lowering expenses while growing effectivity and maintaining the mannequin's performance energy and quality in the AI industry sent "shockwaves" through the market. Why price efficiency matter in AI? I asked why the stock prices are down; you simply painted a constructive picture! Is that this why all of the massive Tech stock costs are down? Actually, the rationale why I spent a lot time on V3 is that that was the mannequin that really demonstrated quite a lot of the dynamics that seem to be generating so much shock and controversy. It has the power to suppose through an issue, producing much increased high quality outcomes, particularly in areas like coding, math, and logic (but I repeat myself). Another large winner is Amazon: AWS has by-and-large did not make their very own high quality model, however that doesn’t matter if there are very high quality open source models that they can serve at far decrease costs than expected.
The medical area, though distinct from arithmetic, additionally calls for robust reasoning to offer reliable answers, given the high standards of healthcare. DeepSeek v3 demonstrates superior efficiency in arithmetic, coding, reasoning, and multilingual tasks, persistently achieving top ends in benchmark evaluations. The timing aligns with industry shifts towards specialized AI hardware - NVIDIA’s Hopper architecture powers 78% of new AI supercomputers as of Q1 2025. FlashMLA’s Hopper-particular optimizations, together with Tensor Memory Accelerator (TMA) utilization and 4th-gen NVLink compatibility, give adopters speedy efficiency advantages. I don’t know the place Wang acquired his info; I’m guessing he’s referring to this November 2024 tweet from Dylan Patel, which says that DeepSeek had "over 50k Hopper GPUs". I’m not sure I understood any of that. If privacy is a concern, run these AI models locally on your machine. Australia: The Australian authorities has banned DeepSeek from all government devices following advice from security businesses, highlighting privacy dangers and potential malware threats.
With the bank’s repute on the line and the potential for resulting financial loss, we knew that we wanted to act rapidly to stop widespread, lengthy-term harm. Learn set up, optimization, and superior tricks to unlock its full potential. Combined with 119K GPU hours for the context size extension and 5K GPU hours for post-training, DeepSeek-V3 prices solely 2.788M GPU hours for its full training. Consequently, our pre- training stage is completed in less than two months and prices 2664K GPU hours. More importantly, a world of zero-value inference increases the viability and likelihood of products that displace search; granted, Google will get decrease prices as properly, however any change from the established order is probably a net detrimental. SWE-Bench is extra well-known for coding now, however is costly/evals agents moderately than models. The United States currently leads the world in chopping-edge frontier AI fashions and outpaces China in other key areas reminiscent of AI R&D. The key implications of these breakthroughs - and the half you want to grasp - solely turned obvious with V3, which added a brand new method to load balancing (additional reducing communications overhead) and multi-token prediction in training (additional densifying each training step, once more decreasing overhead): V3 was shockingly cheap to prepare.
Should you have any kind of queries regarding where by and also the best way to utilize Free DeepSeek online, it is possible to e mail us on our own web-site.
댓글목록
등록된 댓글이 없습니다.