인사말
건강한 삶과 행복,환한 웃음으로 좋은벗이 되겠습니다

The Reality About Deepseek
페이지 정보
작성자 Leandro Hooton 작성일25-03-09 13:47 조회5회 댓글0건본문
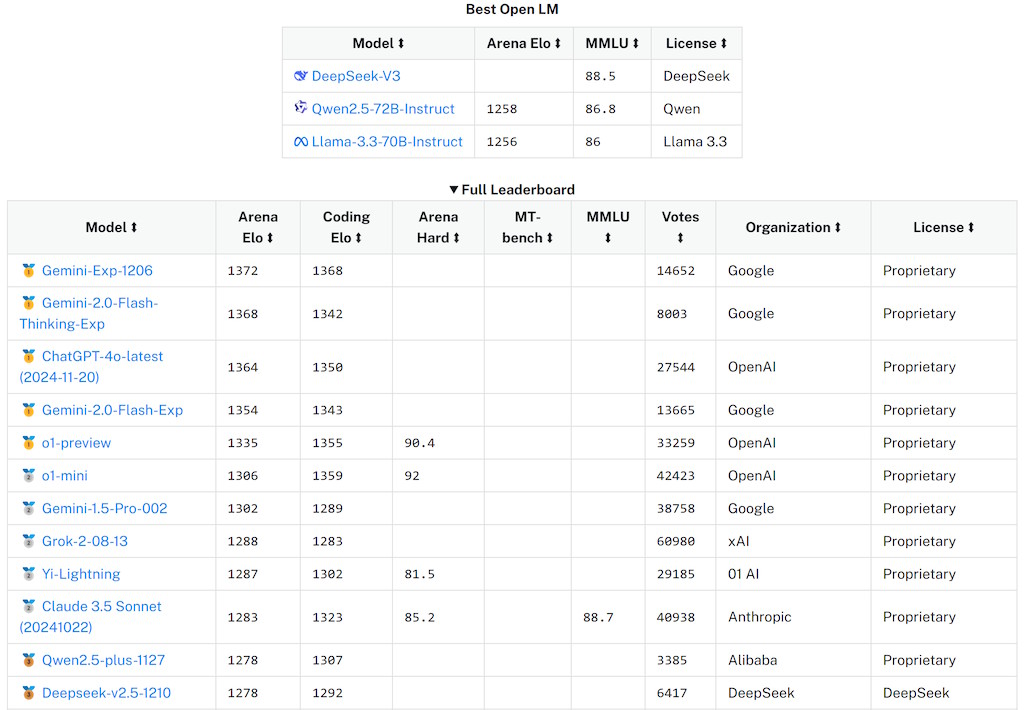 Wang also claimed that DeepSeek has about 50,000 H100s, despite lacking proof. Probably the most striking result of R1-Zero is that, despite its minimal steering, it develops effective reasoning methods that we would acknowledge. In phrases, the specialists that, in hindsight, appeared like the great experts to seek the advice of, are asked to be taught on the example. And just like CRA, its final update was in 2022, in fact, in the very same commit as CRA's final replace. Obviously the final 3 steps are where the majority of your work will go. The last time the create-react-app bundle was updated was on April 12 2022 at 1:33 EDT, which by all accounts as of scripting this, is over 2 years ago. And whereas some issues can go years with out updating, it's important to appreciate that CRA itself has a variety of dependencies which have not been updated, and have suffered from vulnerabilities. While we encourage everybody to try new fashions and tools and experiment with the ever-evolving possibilities of Generative AI, we wish to also urge elevated caution when utilizing it with any sensitive data. Similarly, larger general fashions like Gemini 2.0 Flash present advantages over smaller ones such as Flash-Lite when coping with longer contexts.
Wang also claimed that DeepSeek has about 50,000 H100s, despite lacking proof. Probably the most striking result of R1-Zero is that, despite its minimal steering, it develops effective reasoning methods that we would acknowledge. In phrases, the specialists that, in hindsight, appeared like the great experts to seek the advice of, are asked to be taught on the example. And just like CRA, its final update was in 2022, in fact, in the very same commit as CRA's final replace. Obviously the final 3 steps are where the majority of your work will go. The last time the create-react-app bundle was updated was on April 12 2022 at 1:33 EDT, which by all accounts as of scripting this, is over 2 years ago. And whereas some issues can go years with out updating, it's important to appreciate that CRA itself has a variety of dependencies which have not been updated, and have suffered from vulnerabilities. While we encourage everybody to try new fashions and tools and experiment with the ever-evolving possibilities of Generative AI, we wish to also urge elevated caution when utilizing it with any sensitive data. Similarly, larger general fashions like Gemini 2.0 Flash present advantages over smaller ones such as Flash-Lite when coping with longer contexts.
The Facebook/React crew have no intention at this point of fixing any dependency, as made clear by the truth that create-react-app is no longer up to date and they now suggest different tools (see further down). Nevertheless it positive makes me surprise simply how a lot money Vercel has been pumping into the React group, how many members of that group it stole and how that affected the React docs and the workforce itself, both straight or by means of "my colleague used to work right here and now could be at Vercel they usually keep telling me Next is great". The question I requested myself typically is : Why did the React staff bury the mention of Vite deep inside a collapsed "Deep Dive" block on the beginning a new Project web page of their docs. In 2020, High-Flyer established Fire-Flyer I, a supercomputer that focuses on AI deep studying. SWC depending on whether or not you use TS.
Depending on the complexity of your existing utility, finding the right plugin and configuration would possibly take a bit of time, and adjusting for errors you might encounter may take some time. The research revealed that specialised reasoning models acquire bigger benefits over normal models as context length and considering complexity enhance. Do giant language fashions actually need giant context windows? DeepSeek has compared its R1 mannequin to some of the most superior language fashions within the business - particularly OpenAI’s GPT-4o and o1 models, Meta’s Llama 3.1, Anthropic’s Claude 3.5. Sonnet and Alibaba’s Qwen2.5. Specialized reasoning fashions equivalent to o3-mini outperform general fashions, especially on formal problems. Google DeepMind introduces Big-Bench Extra Hard (BBEH), a new, significantly more demanding benchmark for large language fashions, as current prime models already achieve over 90 % accuracy with Big-Bench and Big-Bench Hard. Tests with completely different fashions present clear weaknesses: The very best common-goal mannequin, Gemini 2.Zero Flash, achieves solely 9.8 % accuracy, while the perfect reasoning model, o3-mini (high), achieves 44.8 percent. While it wiped nearly $600 billion off Nvidia’s market value, Microsoft engineers had been quietly working at pace to embrace the partially open- source R1 model and get it prepared for Azure prospects.
 While modern LLMs have made important progress, BBEH demonstrates they remain removed from achieving general reasoning capacity. However, DeepSeek V3 makes use of a Multi-token Prediction Architecture, which is a straightforward but effective modification the place LLMs predict n future tokens utilizing n impartial output heads (the place n can be any positive integer) on top of a shared mannequin trunk, lowering wasteful computations. Step 2: Further Pre-training utilizing an prolonged 16K window size on an additional 200B tokens, leading to foundational fashions (Free DeepSeek-Coder-Base). As a part of our continuous scanning of the Hugging Face Hub, we have began to detect several models which are high quality-tuned variants of DeepSeek models that have the aptitude to run arbitrary code upon mannequin loading, or have suspicious architectural patterns. Vercel is a large company, and they've been infiltrating themselves into the React ecosystem. Microsoft’s security researchers within the fall observed individuals they consider could also be linked to DeepSeek exfiltrating a big amount of knowledge using the OpenAI software programming interface, or API, stated the folks, who requested to not be identified as a result of the matter is confidential. Both are massive language fashions with superior reasoning capabilities, different from shortform query-and-answer chatbots like OpenAI’s ChatGTP. The system recalculates certain math operations (like RootMeanSquare Norm and MLA up-projections) throughout the again-propagation process (which is how neural networks study from errors).
While modern LLMs have made important progress, BBEH demonstrates they remain removed from achieving general reasoning capacity. However, DeepSeek V3 makes use of a Multi-token Prediction Architecture, which is a straightforward but effective modification the place LLMs predict n future tokens utilizing n impartial output heads (the place n can be any positive integer) on top of a shared mannequin trunk, lowering wasteful computations. Step 2: Further Pre-training utilizing an prolonged 16K window size on an additional 200B tokens, leading to foundational fashions (Free DeepSeek-Coder-Base). As a part of our continuous scanning of the Hugging Face Hub, we have began to detect several models which are high quality-tuned variants of DeepSeek models that have the aptitude to run arbitrary code upon mannequin loading, or have suspicious architectural patterns. Vercel is a large company, and they've been infiltrating themselves into the React ecosystem. Microsoft’s security researchers within the fall observed individuals they consider could also be linked to DeepSeek exfiltrating a big amount of knowledge using the OpenAI software programming interface, or API, stated the folks, who requested to not be identified as a result of the matter is confidential. Both are massive language fashions with superior reasoning capabilities, different from shortform query-and-answer chatbots like OpenAI’s ChatGTP. The system recalculates certain math operations (like RootMeanSquare Norm and MLA up-projections) throughout the again-propagation process (which is how neural networks study from errors).
댓글목록
등록된 댓글이 없습니다.